




Published by Microsoftthe valleyIt is a voice synthesis artificial intelligence that can reproduce human voices with just 3 seconds of voice samples. VALL-E supports languages other than English.val-exIt was posted on github.
GitHub – Plachtaa/VALL-EX: An open source implementation of the Microsoft VALL-E X Zero-shot TTS sample. The demo is available at https://plachtaa.github.io
https://github.com/Plachtaa/VALL-EX
You can find out what type of AI VALL-E is by reading the following article.
Microsoft announces ‘VALL-E’ speech synthesis AI technology that can reproduce a human voice from just a 3-second sample

VALL-E X is an extension of VALL-E that uses both SL speech and TL text as prompts. For example, by entering “speech spoken in English” and “sentences in Chinese”, it is possible to read the speech reproduced in Chinese.
About VALL-E X, Microsoft(PDF file)Research papersand model overviews, but not the source code or pre-trained models.Nanyang Technological UniversitySongting Liu (Electrical and Electronic Engineering Student)feather) The staff trained its own model to reproduce VALL-EX from scratch and released the source code and model.
VALL-E X from Microsoft only supports English and Chinese, but VALL-E X from Plachta is also compatible with Japanese. You can try Mr. Plachta VALL-EX’s Hugging Face demo below.
VALL EX – Hugging Face Space from Plachta
https://huggingface.co/spaces/Plachta/VALL-EX
When you get to the Hugging Face demo page, it looks like this.
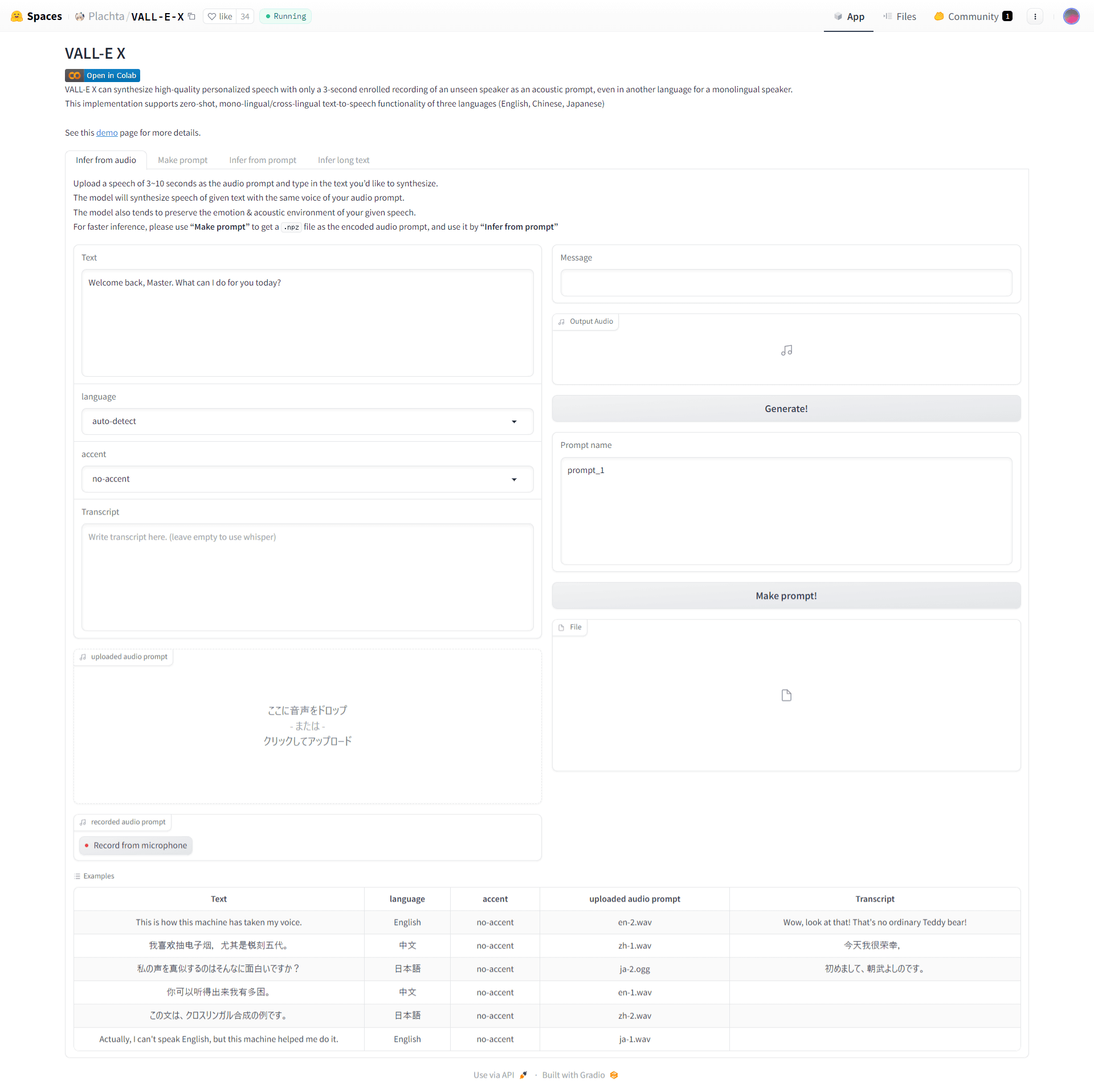
This time, read the news in English, so let’s read the next audio file and create a welcome sound in Japanese.
Load the text you want to read into Text, the language of the text into Language, and the original audio into Uploaded Sound Map, and then click Create!
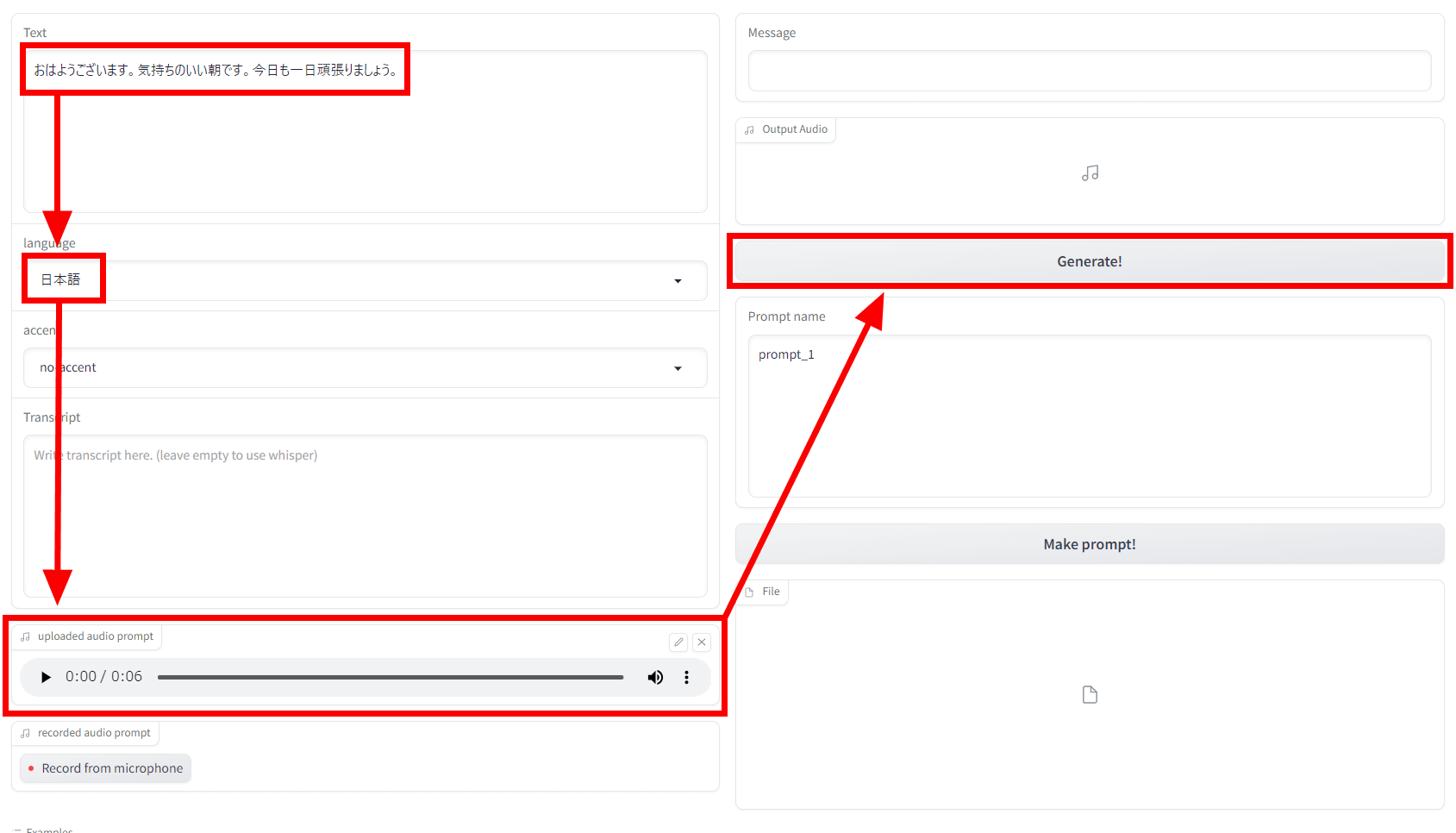
After waiting for about 3 minutes, generated content and generated audio were displayed in the upper right.
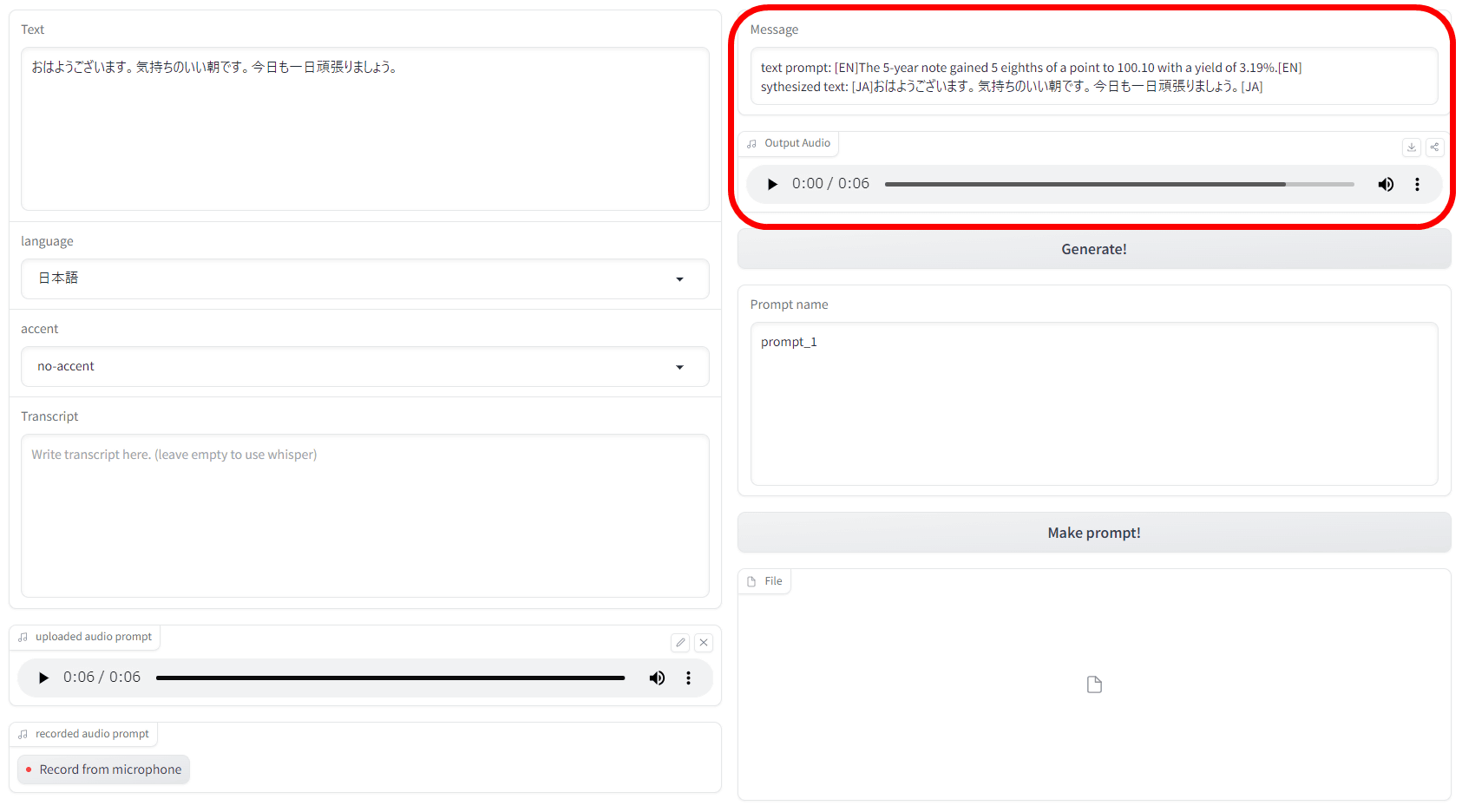
The already created sound is like this. Because the original sound is only a few seconds short, although there is slight distortion, the tone is close to the original sound.
An example of the sound generated by Mr. Plachta’s VALL-EX is also available on the demo page below.
the valley
https://plachtaa.github.io/
Copy the title and URL of this article

“Travel maven. Beer expert. Subtly charming alcohol fan. Internet junkie. Avid bacon scholar.”
More Stories
It's better to call it a digital camera. The Xperia 1 VI lets you take any kind of photo | Gizmodo Japan
Google may be developing a new device called “Google TV Streamer” to replace “Chromecast”
What do you want to talk about? “Persona 3 Reload” recommendation campaign is running until July 31st! |.Persona Channel