





American technology companiesAl-Maraj Agency for Artificial Intelligence“It will be held on October 22 (Tuesday) using artificial intelligence video generation technology.”Gen 3 AlphaAs a function within ', we have released 'Act-One', a tagless facial motion capture function that transfers character images from facial motion reference videos. Target users are users of paid plans (standard or higher with monthly or annual billing).
Act-One allows you to faithfully capture the essence of an actor's performance and pass it on to your generation. While traditional facial animation pipelines involve complex, multi-step workflows, Act-One works with a single driving video that can be shot on something as simple as a cell phone.
Without the need for motion capture or character rigging, Act-One is able to translate performances from a single input video across a myriad of different character designs and in many different styles.
The first act depends on the performerFaithfully capture the essence of performance and replace it with AI video generationYou can. Traditional facial animation pipelines require complex workflows, but with Act-One, all you need is a single video that can be shot with a camera as simple as a smartphone.
With no motion capture or manipulation required, Act-One can create countless different character designs and different styles of performance from a single input video.
One of the model's strengths is producing cinematic and photorealistic output across a wide number of camera angles and focal lengths. Allowing you to create emotional performances with a depth of character previously impossible and opening new horizons for creative expression.
With Act-One, eye lines, precise expressions, speed and delivery are faithfully represented in the final generated output.
One of the strengths of this model is thatCreate and produce cinematic, realistic images with multiple camera angles and focal lengths.He is. It is possible to create emotional performances with a depth of character that would not have been possible with traditional video generation AI, opening up new horizons for creative expression.
In the first chapterLine of sight, subtle changes in facial expression, pauses, and speaking styleAll this will be honestly expressed in the created video.
To use it, simply upload a facial performance video you've shot, select or upload a reference selfie from the presets, and run Create.
-
1: Upload the facial performance video -

2: Select the image of the reference character
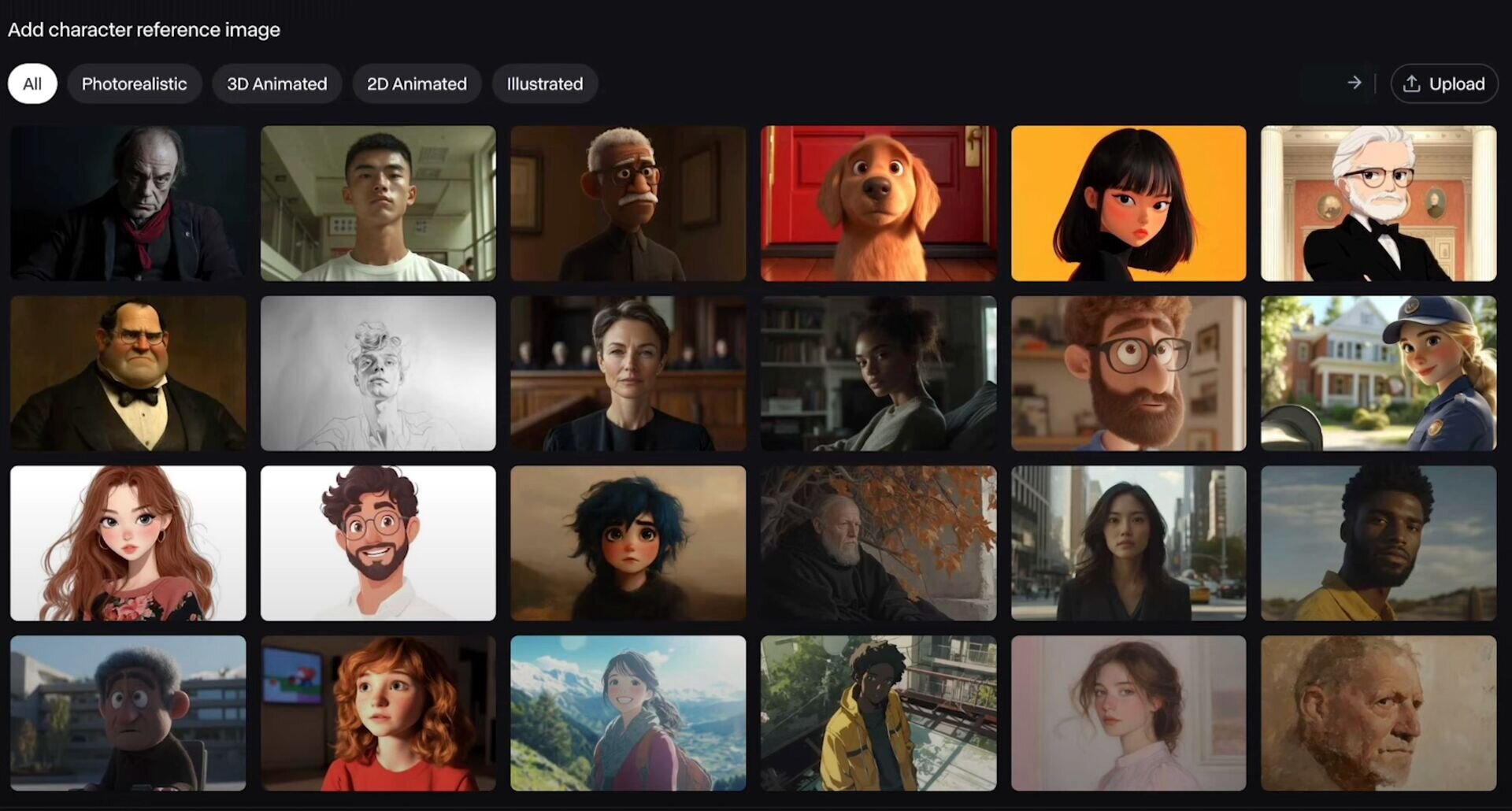

Act-One requires 10 units/s in Gen-3 Alpha. The maximum video that can be created is 30 seconds, 1280 x 768, 24 fps. There are some necessary and recommended conditions for its use, such as recording performance videos from the front, and not photographing characters from the side or the full body to reflect their performance. These conditions and precautions are listed below.
■ Build with Act-One on Gen-3 Alpha
https://help.runwayml.com/hc/en-us/articles/33927968552339-Creating-with-Act-One-on-Gen-3-Alpha
The Standard plan is billed annually at $144 (about 22,000 yen). “Built with Gen-3 Alpha and Act-One“It is written.
Information related to CGWORLD
● Video to video conversion is now available with Runway's AI video generation “Gen-3 alpha”! Supports video input and output consistency control for up to 10 seconds

Runway AI launches the Video to Video function of its “Gen-3 Alpha” video generation AI to the public. Target users are users of paid plans (standard or higher with monthly or annual billing).
https://cgworld.jp/flashnews/202409-Gen3AlphaVideo.html
● Luma AI video generation “Dream Machine 1.6” released! Supports camera movement control, and version 1.5 also supports custom text display

Luma AI has released the latest version 1.6 of its “Dream Machine” video generation AI to the public. In both text-to-video and image-to-video, camera movement instructions can now be generated from text input suggestions.
https://cgworld.jp/flashnews/202409-DreamMachine.html
● Adobe will release the beta version of its AI video creation model “Firefly Video Model” later this year! It plans to integrate the functionality into Premiere Pro, emphasizing that the design is safe for commercial use

Adobe announced on its blog that it will launch a beta version of its “Firefly Video Model” video generation AI model in the second half of 2024, and released samples generated by the model.
https://cgworld.jp/flashnews/202409-FireflyVideo.html

“Travel maven. Beer expert. Subtly charming alcohol fan. Internet junkie. Avid bacon scholar.”
More Stories
CEO/Director of Sandbox ADV “Core Keeper,” which is selling well in Japan, asks for “ideas for communicating community love” in Japanese
Looking at the distant universe from a 5,640 meter mountain peak with little water vapor | University of Tokyo
Wolf-Rayet star “WR 140”: a tree-ring-like structure that forms every 8 years[الصورة الفضائية اليوم]|